1.概述
在分析这个问题之前,其实要先明白一个事情:
我们为啥要研究如何控制百度抓取和展现的问题?
原因在于:一个网站有成千上万的网页;并不需要每一个页面都展现给客户;也就是说不需要每一个页面都需要百度去抓取;同时每天百度来抓取我们网站的力度是有限的,我们要保证百度抓取的效率;把一些不相干的,杂乱的因素帮百度蜘蛛清理掉;让百度蜘蛛专心抓取我们认为能够对访客有用的网页。
日志分析完之后,了解了目前蜘蛛爬行的状况,重点就一些列表页,不希望蜘蛛对它进行爬行,同时有一些列表页已经被索引,要从索引中将这些列表页删除; 下面将论述如何来处理这些页面。
2.如何不让蜘蛛爬行和抓取列表页
对于不希望蜘蛛爬行和索引的列表页,可进行以下处理:
1.在robots.txt 文件中,将不希望访问的页面进行Disallow,如下图所示:

对于: User-agent 的处理,使用的是 * ;是针对所有的搜索引擎蜘蛛;
在此robots.txt中,经过长期的日志分析,已经去除了很多不相关的爬行目标,比如:图片类,样式表类,JS等脚本文件类等;
2.对于具体的产品的供应商列表页,这类页面想索引,但是分页页面不希望被索引。
这里面的分页部分,对于链接Url进行nofollow,如下图所示:

3.对于图片类的,我不希望进行索引,并同样通过robots.txt进行控制,如下图所示:

1.在robots.txt 文件中,将不希望访问的页面进行Disallow,如下图所示:
对于: User-agent 的处理,使用的是 * ;是针对所有的搜索引擎蜘蛛;
在此robots.txt中,经过长期的日志分析,已经去除了很多不相关的爬行目标,比如:图片类,样式表类,JS等脚本文件类等;
2.对于具体的产品的供应商列表页,这类页面想索引,但是分页页面不希望被索引。
这里面的分页部分,对于链接Url进行nofollow,如下图所示:
3.对于图片类的,我不希望进行索引,并同样通过robots.txt进行控制,如下图所示:
3. 如何将已经索引的列表页从百度索引中删除
1.对于已经收录的列表页,特别是一些希望客户访问的产品供应商页的分页列表;可进行noindex,nofollow如下处理:
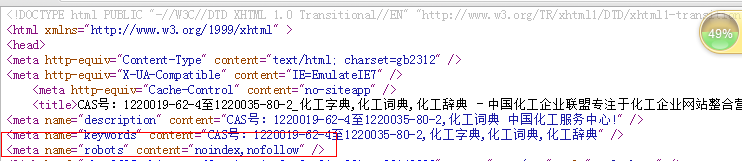
2.对于一些目前已经被百度索引,但是确实已经不存在的页面,可直接编写一个sitemap文件,到百度站长平台进行死链提交;
当然,如果希望百度继续索引你的网页,但是不在快照中显示,那么我们可以通过在网页中增加meta 标签的方式来处理设置:
<meta name=“robots” content=“noarchive”> 这个是针对所有搜索引擎的;
如果想仅针对百度,可以这么写:
<meta name=“Baiduspider” content=“noarchive”>
不过一般不建议这么做。
以上是我目前对于自己网站不让百度收录的一些做法。
1.对于已经收录的列表页,特别是一些希望客户访问的产品供应商页的分页列表;可进行noindex,nofollow如下处理:
2.对于一些目前已经被百度索引,但是确实已经不存在的页面,可直接编写一个sitemap文件,到百度站长平台进行死链提交;
当然,如果希望百度继续索引你的网页,但是不在快照中显示,那么我们可以通过在网页中增加meta 标签的方式来处理设置:
<meta name=“robots” content=“noarchive”> 这个是针对所有搜索引擎的;
如果想仅针对百度,可以这么写:
<meta name=“Baiduspider” content=“noarchive”>
不过一般不建议这么做。
以上是我目前对于自己网站不让百度收录的一些做法。